iptables 介绍
为什么需要学习iptables ?
Linux防火墙、NAT、Kubernetes等很多地方都用到iptables,了解它很重要。
本文主要信息来源是netfilter官网推荐的iptables教程。
本文目的:了解iptables原理;了解iptables配置方法,看懂iptables配置脚本
什么是iptables
iptables经常被与netfilter一同提起。
netfilter是一个工作在Linux内核层面的网络数据包处理框架,提供了包过滤、地址或端口转换、包修改等功能;具体来说,就是在数据包处理路径上的特定位置触发对应的hook,这就是我们常说的5个chain、4个table。
iptables是一个工作在用户态的命令行工具,用于在上述chain和table上配置规则集,以自定义包过滤规则、地址转换规则等。常见的用途如实现防火墙。
学习iptables,是在学什么
首先,学习网络协议栈基础知识,需要精确到数据包结构;其次,学习chain和table的详细组成、写作方式;最后,学习iptables命令的使用方法。
网络基础 - TCP/IP协议栈
TCP/IP是老生常谈了,不过多少次重复都不为过。
概览
我们常说的TCP/IP协议栈,或者TCP/IP Stack,指的就是TCP/IP构成的多层模型,在Linux中,就是指内核对该多层模型的实现。该协议到底分为几层,没有一个明确的共识,一般来说是四层,如下:

也有说五层的,还有OSI标准的7层,它们实际对应关系如下
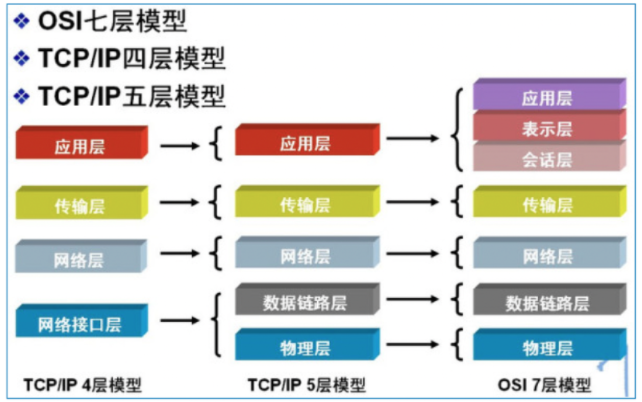
理论来说,iptables应该工作在二层,即网络互联层,但实际上它也提供三层(传输层)的跟踪配置能力,因此,我们需要详细了解的协议主要有IP、ICMP、TCP、UDP、SCTP。控制为主,而控制主要集中在数据包头部,因此会详细解析头部字段含义。
IP协议
IP是无状态协议,主要解决数据去哪的问题。头部分析如下

含义解读如下
| 段 | 含义 |
|---|---|
| Version | 版本。0100 - IPV4 0110 IPV6 |
| IHL | Internet Header Length,IP头长度,单位:word(即32 bit)。 为啥需要这个呢,因为Options的长度可选,所有要用它来确定总长 |
| TOS/DSCP/ECN | TOS: Type Od Service, 总共八位,它们主要是在路由器等硬件设施上使用,每位的含义如下 0-2:优先字段 3:正常或者低延迟 4:正常或者高吞吐量 5:正常或高可靠性 6-7:预留 这部分还经过了两个迭代:DSCP和ECN,这里不深入 DSCP: Differentiated Services Code Point 差异化服务码点 ECN: Explicit Congestion Notification 显式阻塞通知 |
| Total Length | 整个IP数据包的总长度,包括头部。单位为字节 |
| Identification | 唯一标识。用于数据分片后再组装时的识别。和Offset结合一起使用 |
| Flags | 分片标识 bit 0:保留 bit 1:当前数据包是否可分片。 0-不可分片,1-可分片 bit 2:当前数据包是否是分片的最后一片。0-是最后一个,1-后面还有 |
| Fragment Offset | 分片位移 |
| Time To Live | 有效期。单位:跳。每经过一次转发,TTL减一,当为0时会被销毁。 用于避免一个包陷入死循环转发 |
| Protocol | 上一层数据的协议。如TCP、UDP等 |
| Header Checksum | 头部校验和。每经过一跳都会重新计算,因为TTL变了 |
| Source Address | 源地址 |
| Destination Address | 目标地址 |
| Options | 可选项,最长可占40个字节。可以包含时间戳、SACK等 |
| Padding | 由于头部是按照word为单位的,所以如果Options的长度不足一个word,则需要Padding补齐 |
那么问题来了,Source Address子弹只有四个字节,那么IPV6怎么表示呢?
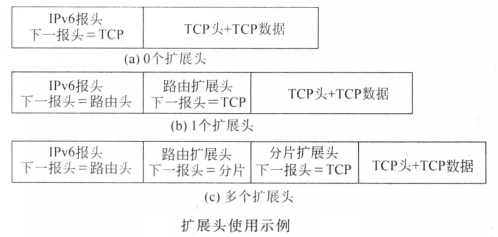
IPV6的头部和IPV4不一样,具体来说有两点
- 地址字段用128位表示,而不是现在的32位
- Options字段取消了,取而代之的各种扩展头。如TCP扩展头、路由扩展头等,当然从实际作用来说和IPV4差不多
ICMP协议
ICMP用于主机到主机或主机到网关之间的基本错误报告。
ICMP有点特殊,从作用上看,它是构建在IP协议之上,但是其包结构有何IP类似。并且,ICMP是IP的不可分割的一部分,每个IP的实现都必须包含ICMP。

| 字段 | 含义 |
|---|---|
| 头部字段 | 和IP协议的头部字段一样,我们就不再赘述 |
| Type | ICMP类型 |
| Code | ICMP类型下的具体代码 |
Type和Code的组合有很多种,参考附件:https://www.frozentux.net/iptables-tutorial/iptables-tutorial.html#ICMPTYPES
不同的类型拥有不同的报文body,常见的类型如下
Echo
echo请求type=8,回复type=0

- id:echo请求的序列号,恢复时针对序列号恢复
- sn:主机序列号,递增
- data:默认为空。也可以包含用户指定的数据
目标不可达
type=3,Code可能是0-15,代表了各种不可达的原因

TCP协议
TCP是有状态协议,简要描述一下TCP协议的三个过程
- 握手:客户端发送SYN包,服务端恢复SYN/ACK表示接收,或者SYN/RST表示拒绝,客户端收到接受的包后,再发送一个ACK数据包。至此连接建立,握手成功
- 数据发送:客户端每发送一个数据包,服务端都要响应ACK表示收到,否则客户端会重试
- 挥手:一端发送FIN包,表示要结束连接;另一端回复FIN/ACK,此时FIN发送端不能再发送任何数据,但是接收端可以,此时只是关闭了单向数据传送;如果要关闭另一个方向的传送,反向重复上述操作即可。
要注意,握手是在确定双方都同一传输数据;挥手也是在确定双方都同意关闭连接。而由于挥手时存在半关闭状态,自己的连接是否关闭只有自己说了算(因为只要自己才知道是否还有数据没传输完),所以需要自己发起FIN请求。
TCP的头部如下
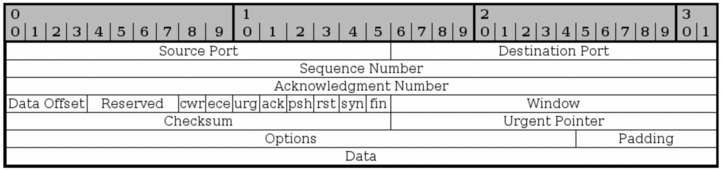
| 段 | 含义 |
|---|---|
| Source Port | 源端口。端口对应的是进程。IP+Port能够定位到指定主机的指定进程。 |
| Destination Port | 目标端口 |
| Sequence Number | 序号,安全传输的保证,标识每一个数据包,接收方响应ACK时带上SN,就知道改包是否被正常接收 |
| Acknowledgement Number | 与上面的序号对应。这是在响应时候确认那个序号的包被成功接收 |
| Data Offset | 标识标头长度。它标记的是正文数据Data开始位置的word偏移数量。word即32位 |
| Reserved | 保留 |
| cwr | Congestion Window Reduced,用于发送方通知接收方数据拥塞窗口减小 |
| ece | ECN的回声。前面说过,ECN是阻塞通知的意思 |
| urg | 是否使用紧急指针字段 |
| ack | 标识这个数据包是对收到的另一个数据包的回复 |
| psh | PUSH,告诉中间主机将数据发送给最终目标主机,无论是否发生拥塞 |
| rst | RESET,告诉另一端断开TCP连接,主要是异常断开 |
| syn | 同步序列号位,建立连接时使用 |
| fin | 发起关闭连接时使用 |
| Window | 接收方用该字段告诉发送方目前允许接收多少数据。这是在一个ACK报文中一起携带的 |
| Checksum | 校验和 |
| urgent Pointer | 如果连接中有重要数据需要接收方立即处理,通过urg标识和紧急指针,后者标识了紧急数据的结束位置 |
| Options | 选项,有专门的TCP选项 |
| Padding | 头部不足一个word时,补0 |
| Data | 正文数据 |
UDP协议
它是无状态的,没有任何的错误检测。适合查询/响应类应用,如DNS。
TCP协议虽然可靠,但是可靠机制带来了很多开销,相对地,UDP非常地简单,仅包含数据传输,因此我们可以在其上构建我们自己的协议。比如HTTP3.0的QUIC协议,正如其全称 Quick UDP Internet Connection 表示的含义一样。

有关QUIC协议和HTTP3.0的内容,这篇文章不错:[https://blog.51cto.com/u_6315133/3122045](
SCTP协议
这也是一个传输层协议,类似TCP和UDP。它也是一个面向连接的可靠的协议,与TCP不同的是,它提供了更高的可靠性。
- SCTP面向消息,支持单个消息称帧。而TCP是面向字节的。
- 全双工传输
- 多流功能:即常说的多路复用功能,类似HTTP2,分为多个stream,每个stream都由stream id标识,丢包也只会影响该stream的数据,其它stream不受影响。这样可以提高传输效率。
- 多宿主功能:指的是一个SCTP端点可以对应多个IP地址,其中有一个为主,其它的为副。当主IP接收失败时,会重发到副IP地址。
- 能够通过INIT快防止DoS攻击
SCTP通讯的三个过程
初始化和关联
- 发起方发送INIT,接收方响应INIT-ACK,INIT-ACK中带有Cookie配置信息
- 发起方发送COOKIE-ECHO进行初始连线,接收方响应COOKIE-ACK。然后就可以发送数据了。
这里的COOKIE机制可以防止TCP机制的SYN攻击,TCP协议中,发起方发送SYN,接收方响应SYN/ACK后,发起方不回应ACK,此时接收方会等待一段时间。如果发起方发送大量这种请求,就形成了SYNC攻击(DoS攻击的一种)
数据发送和控制会话
- 数据发送时用DATA块,响应时用SACK块。这个和TCP差不多
- HEARTBEAT 和 HEARTBEAT ACK块用于保持连接不断开
- ERROR用于传输过程中的错误通知
关闭和中止
- 优雅关闭用 SHUTDOWN块。SCTP没有TCP那样的半关闭状态,当一端发起关闭时,另一端就不能发送数据了。取而代之它的关闭流程如下
- 发起方发送所有缓冲区的数据,然后发送SHUTDOWN块
- 接收方搜到SHUTDOWN块,发送本地缓冲区所有的数据,发送SHUTDOWN ACK
- 发起方收到后,发送SHUTDOWN COMPLETE,至此关闭完成
- 强制关闭用ABORT块。缓冲区的所有数据被丢球,接收方也一样
- 优雅关闭用 SHUTDOWN块。SCTP没有TCP那样的半关闭状态,当一端发起关闭时,另一端就不能发送数据了。取而代之它的关闭流程如下
SCTP连接和终止图示如下
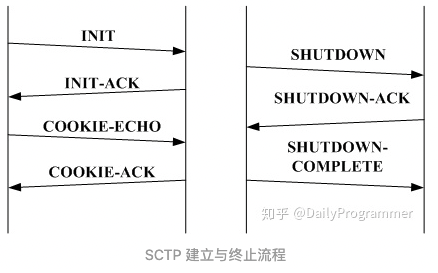
怎么看,都有点像四层协议的部分特性下放到三层来了
SCTP的头部分为通用头部和具体块的结构(有多种类型的块,每个块的结构不一样)。

通用头部如下。其中Verification Tag用于验证数据包是否来自正确的发送者。

块结构如下

块类型如下

这里列举建立连接时的四个块
INIT
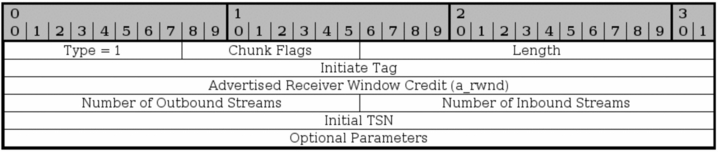
INIT ACK
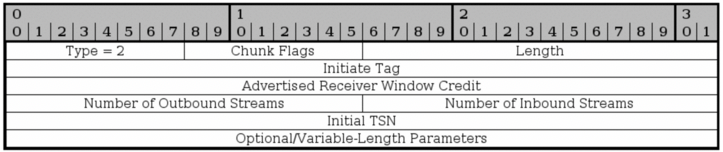
ACK和INIT完全相同,只是添加了Cookie和一些其它参数。Cookie参数结构如下。可见Cookie就是一个随机二进制值。

COOKIE ECHO

COOKIE ACK

理解iptables
IP过滤
IP过滤就是决定数据包如何处理的过程。Linux操作系统的netfilter/iptables是IP过滤的一种实现,也可以称作防火墙。一些物理网络防火墙设备也是这个原理。
至于iptables,字面理解,它是工作在IP层执行IP包过滤的,但是实际实现并不严格,它还能根据更高层的TCP等协议和更底层的MAC协议过滤数据包。即跨越了一、二、三层。甚至增加插件后,iptables和netfilter能够在四层进行过滤。这就是iptables远比看起来的复杂。
概念介绍
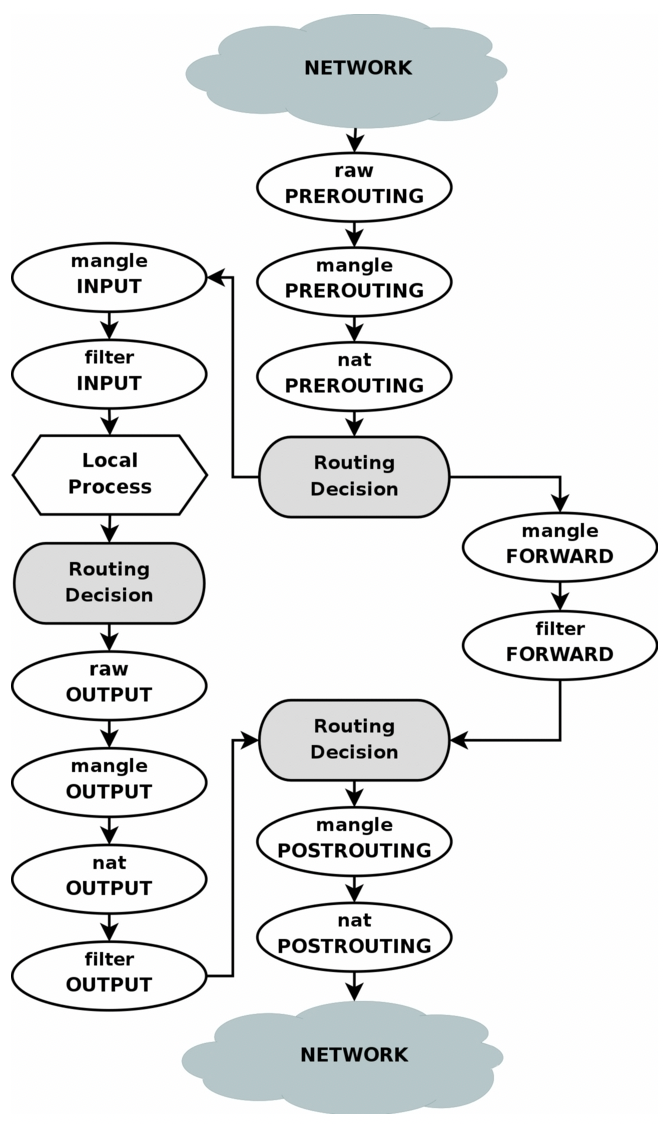
chain:即五个hook位置,为什么叫做chain?因为执行到该hook时,实际上是在该位置的rule链上进行遍历。
- PREROUTING
- INPUT
- FORWARD
- OUTPUT
- POSTROUTING
table:规定了几个记录rule的表
raw
只做一件事:为数据包添加标记,表明该包不被跟踪
mangle
如下事项只能在Mangle表中做,其它地方不能做
- TOS:修改IP报文头的TOS字段,这能够影响路由决策。
- TTL:修改IP报文的TTL
- MARK:为报文添加特殊标识,这能够影响路由决策,也可以影响带宽限制
- SECMARK:添加安全标识
- CONNSECMARK:同上,也是一些安全标识
nat
只能用来做地址转换
- DNAT:修改目标IP地址
- SNAT:修改源IP地址,用以隐藏本机地址
- MASQUERADE:类似SNAT,但更耗费性能
- REDIRECT
filter
用于过滤数据包,以任何我们想要的方式。这是我们操作的最多的地方
rule:一条声明式规则,声明了什么时什么样的包执行什么样的操作
match:匹配规则,iptables可以按照各种包的特征进行匹配
用一个图来解释chain和table的关系
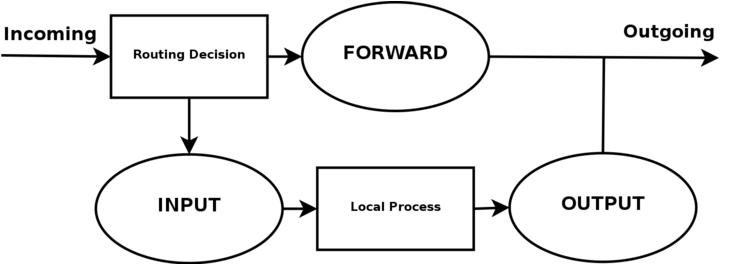
下面这张图可能是更常见的
连接状态跟踪
这是iptables中的一个特殊部分。在 iptables 中,数据包可以与处于四种不同所谓状态的跟踪连接相关联
- NEW
- ESTABLISHED
- RELATED
- INVALID
这些是由内核框架conntrack完成的。它实时跟踪记录了传输层连接的状态,在配置匹配条件时,匹配指定状态的连接的所有数据包。
以TCP为例,状态变化如下。
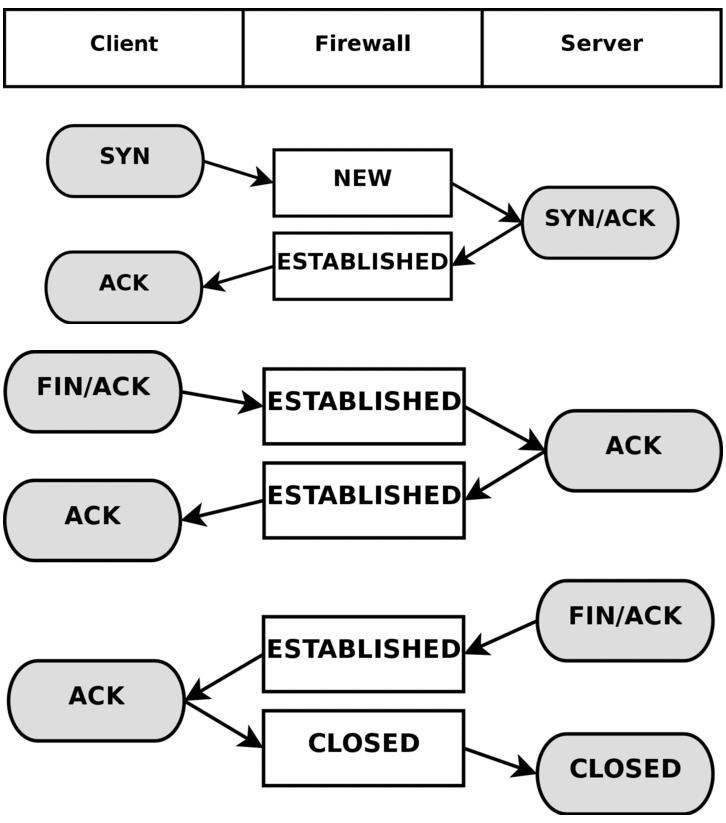
如果有开启连接跟踪,在/proc/net/ip_conntrack文件中能够看到信息,比如
1 | tcp 6 431999 ESTABLISHED src=192.168.1.5 dst=192.168.1.35 \ |
从左到右依次是:协议、一个十进制编码、记录过期时间(s)、状态值、入方向上的地址和端口信息、反向地址和端口信息、预期返回的包数量
iptables命令
1 | iptables [-t table] command [match] [target/jump] |
如上是iptables的常见语法。从左到右依次是 表名、命令、匹配规则、目标操作或跳转目标。其中table可选,如果不指定,默认就是filter表。
命令
| 命令 | 说明 |
|---|---|
| -A –append |
将规则rule到指定chain的最后 iptables -A INPUT … |
| -D –drop |
将rule从执行chain中删除。两种使用方式 1. 指定完整的规则 2. 指定规则的序号:序号chain中从上到下依次递增,1开始 iptables -D INPUT –dport 80 -j DROP, iptables -D INPUT 1 |
| -R –replace |
替换指定位置的rule iptables -R INPUT 1 -s 192.168.0.1 -j DROP |
| -I –insert |
向chain中的指定位置插入rule iptables -I INPUT 1 –dport 80 -j ACCEPT |
| -L –list |
列出指定chain中的所有rule iptables -L INPUT |
| -F –flush |
清空指定chain上的所有rule,和一条一条删除效果一样,只不过更快 iptables -F INPUT |
| -Z –zero |
清空指定chain上的计数器。这些计数器用于计量包数和字节数 iptables -Z INPUT |
| -N –new-chain |
创建一个新的chain iptables -N allowed |
| -X –delete-chain |
删除置顶chain,只有已经被清空的chain,即没有任何rule的chain才能被删除 内建的chain如INPUT等是无法被删除的 iptables -X allowed |
| -P –policy |
为chain设置默认的target或policy,在该chain上,任何没有被rule匹配到的包,都会应用该默认规则。 只有两个合法的target:DROP 和 ACCEPT iptables -P INPUT DROP |
| -E –rename-chain |
重命名chain iptables -E allowed disallowed |
新建chain有什么用?
只有前文所述5个chain是内建的,用户自建的chain并不会被自动hook到数据流中。只能通过以jump的形式从一个已有的chain跳入,待执行完后再跳回。所以新建的chain其实就是一个相对独立的规则集而已(这也是它的最大用途),对内核透明。
匹配规则
match是语法最为复杂的一部分,不同的协议有不同的匹配规则。
通用match
| 匹配项 | 说明 |
|---|---|
| -p —protocol | 指定协议 - 协议只能是 /etc/protocols 文件中存在的,否则会报错 - 可以正向也可以反向。 iptables -A INPUT -p ! tcp 表示非tcp |
| -s —src —source | 来源IP,可以有多种形式。也可以用 ! 运算符反向指定 - 单个IP形式 192.168.0.0 - CIDR形式 192.168.0.0/24 - 子网掩码形式 192.168.0.0/255.255.255.0 |
| -d —dst —destination | 同上,反向而已 |
| -i —in-interface | 指定包的来源接口,如en0。 - 只能在INPUT FORWARD PREROUTING 三个chain使用 - 允许通配,+表示所有接口,en+表示en开头的所有接口 |
| -o —out-interface | 同上,反向而已 |
| -f —fragment | 匹配分段数据包的第二、第三。。。段 如果不指定,就只会匹配未分段的数据包或者分段数据包的第一段 |
隐式match
tcp match
如下匹配仅对 -p tcp 的情况下有效
匹配项 说明 -p —protocol 源端口,可以指定端口号或service,service必须在 /etc/services 文件中存在
可以指定具体端口,也可以指定端口范围 比如 22:80,标识22到80的所有端口 也可以使用取反—dport —destination-port 目标端口,语法同上 —tcp-flags 匹配tcp标记,如SYN/RST/ACK/FIN等,也可用ALL、NONE —syn 遗留语法,和 —tcp-flags SYN,FIN,ACK SYN一个效果 —tcp-option 根据tcp选项匹配 icmp match
只对 -p icmp 的情况有效,它只有一个参数
—icmp-type,即匹配icmp类型
其它协议的match
显式match
显示匹配就是需要通过-m 或 —match的形式指定的参数
比如地址匹配,地址被Linux分为很多类型,根据地址类型的参数有两个,如下
—src-type
iptables -A INPUT -m addrtype –src-type UNICAST
—dst-type
iptables -A INPUT -m addrtype –dst-type UNICAST
还有好多match,如果需要,可以到这里查询
目标或跳转
target/jumps告诉如何处理与规则匹配到的包
什么是target,即两个基本的target:ACCEPT和DROP
什么是jump呢?原理:上面介绍过了,用iptables -N能够创建新的chain,可以在新的chain上定义自己的规则集,但这个chain并非内建的几个chain之一,因此不会被自动执行,此时就需要jump,语法如下
iptables -A INPUT -p tcp -j
上面在INPUT chain中添加了一条rule,将所有tcp协议的包都跳转到自定义chain上,当自定义chain的所有table都执行完成时,它会跳转回原来的chain,即INPUT chain
下面列举所有的target
| target | 说明 |
|---|---|
| ACCEPT | 接受,接受的意思就是啥都不做,放它过去 一旦一个包被接受了,统一table和同一chain的后续规则将被忽略。 但其它table仍然可以对这个包进行处理 |
| DROP | 直接丢弃 |
| CLASSIFY | 将包分类,只对mangle表有效 iptables -t mangle -A POSTROUTING -p tcp –dport 80 -j CLASSIFY –set-class 20:10 |
| CONNMARK | 将整个连接都做上标记,所有表都可用 iptables -t nat -A PREROUTING -p tcp –dport 80 -j CONNMARK –set-mark 4 |
| MARK | 标记匹配到的数据包 |
| DNAT | 指定DNAT的目标地址。只能在nat表的PREROUTING和OUTPUT链中使用 iptables -t nat -A PREROUTING -p tcp -d 15.45.23.67 –dport 80 -j DNAT –to-destination 192.168.1.1-192.168.1.10 |
| SNAT | 指定SNAT的源地址。只能在nat表的PREROUTING链使用 |
| LOG | 记录日志,日志记录是通过syslogd实现的 iptables -t nat -A POSTROUTING -p tcp -o eth0 -j SNAT –to-source 194.236.50.155-194.236.50.160:1024-32000 iptables -A FORWARD -p tcp -j LOG –log-level debug iptables -A INPUT -p tcp -j LOG –log-prefix “输入数据包” |
| TTL | 设置TTL,只能在mangle表使用 iptables -t mangle -A PREROUTING -i eth0 -j TTL –ttl-set 64 |
例子分析
通过iptables-save -c可以将本机的iptables规则集保存到文件,我们将一台布有K3S的机器的规则集贴出来看看
1 | ubuntu@VM-20-5-ubuntu:~$ sudo iptables-save -c |
解读几个关键语法
*raw声明往下到COMMIT之间的行,都是在raw表中
:PREROUTING ACCEPT [8488585:2225268588]这是一个累计状态,表示 PREROUTING这个chain已经接受了 8488585 个数据包,共计2225268588个字节的数据。
[402612:15051273] -A PREROUTING -m comment --comment "kubernetes service portals" -j KUBE-SERVICES这是一条规则,前面是匹配这条规则的累计状态
[包数:字节数]。这条规则说明:经过PREROUTING阶段的的所有数据包,都加上注解,然后跳转到KUBE-SERVICES chain上遍历
总结
iptables关键点
- TCP/IP协议栈
- 数据包在内核中的处理流程
- iptables语法